Séance 8 (16/03/16)
On va récupérer les mots correspondant aux étiquettes : il faut connaître leur rang/indice.
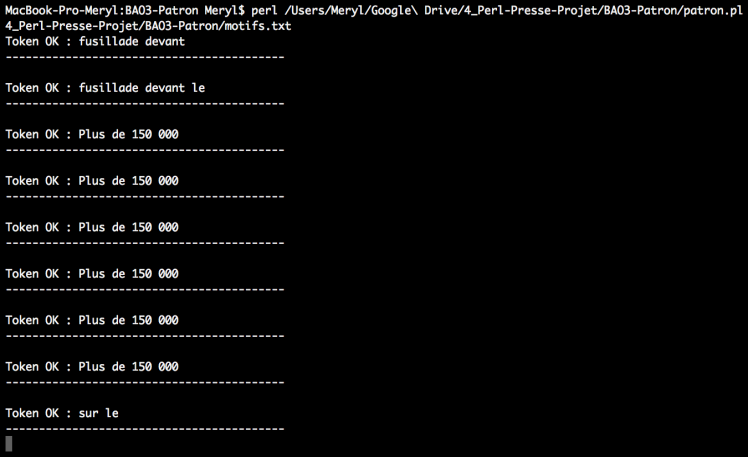
Le script 2 prend les étiquettes morphosyntaxiques en argument :
 Transformation du fichier Cordial en une liste pour comparer cette liste avec les arguments. Liste de toute les chaînes et dans ARGV la sous-liste des éléments du patron.
Transformation du fichier Cordial en une liste pour comparer cette liste avec les arguments. Liste de toute les chaînes et dans ARGV la sous-liste des éléments du patron.
La liste Cordial va être vidée progressivement.
Ici on recherche la séquence NOM-ADJ :
– si ligne de la liste cordial contient NOM, on regarde si la ligne suivante contient ADJ, si oui, on imprime.
Modifier ce programme pour Treetagger.
Comparer les résultats obtenus entre les différents programmes.
Séance 7 (09/03/16) : Début BAO3
BA01 : extraction texte brut
BAO2 : étiquetage cordial et étiquetage Treetagger en xml
BAO3 (1) : travail sur le texte étiqueté par Cordial
BAO3 (2) : travail sur le texte étiqueté par Treetagger avec une feuille de style xslt
BAO3: extraire des séquences de termes associés à des patrons morphosyntaxiques.
Affichage graphique
Aujourd’hui : BAO3 (1): travail sur le texte étiqueté par Cordial
(Deuxième colonne : lemme)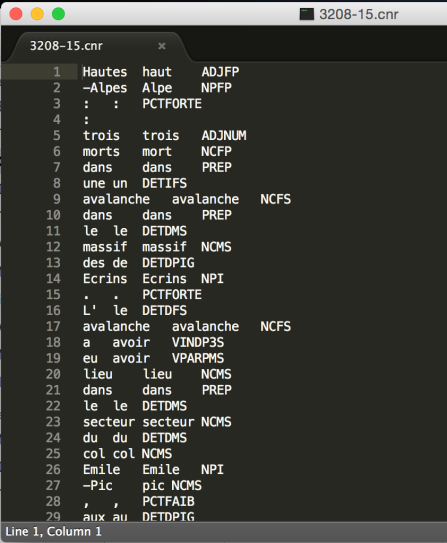
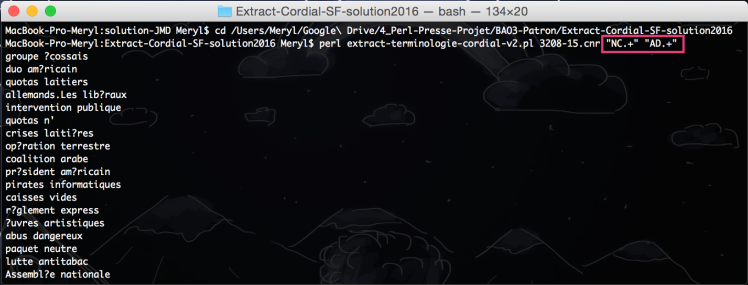
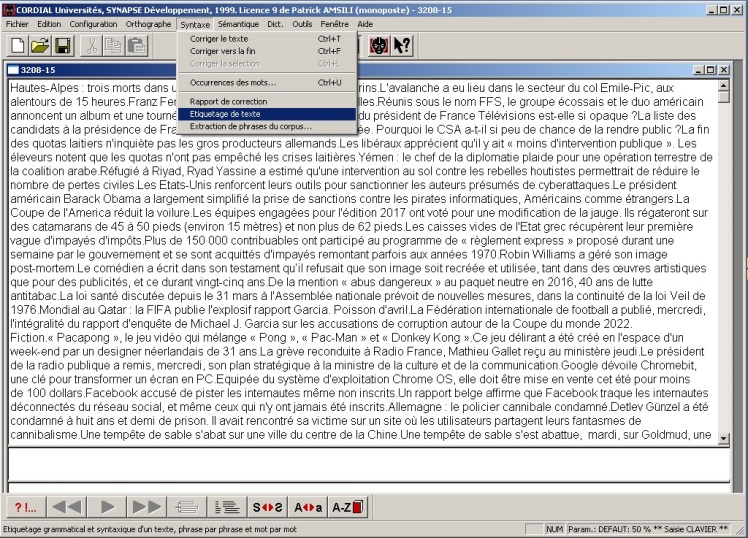
On fait tout ça pour trouver dans les textes des indices qui peuvent permettre une interprétation. On fait une recherche terminologique. Au lieu de faire des statistiques textuelles, on va chercher des indices dans le texte basés sur des patrons morphosyntaxiques (ex: NOM-PREP-NOM). La sortie sera des candidats termes (ex : déplacement en province). Fichier d’entrée : fichier Cordial, fichier programme et fichier des motifs terminologiques :
Capture et analyse de la colonne 3 du fichier cordial et comparaison avec le fichier motif.
Deux étapes :
1) Extraction du contenu des colonnes dans des listes :
– lecture ligne par ligne et ajout dans 3 listes du contenu par colonne
– traitement du fichier par ligne du fichier motif
attention à la ponctuation qui coupe les patrons (traitement phrase par phrase) : délimiteur.
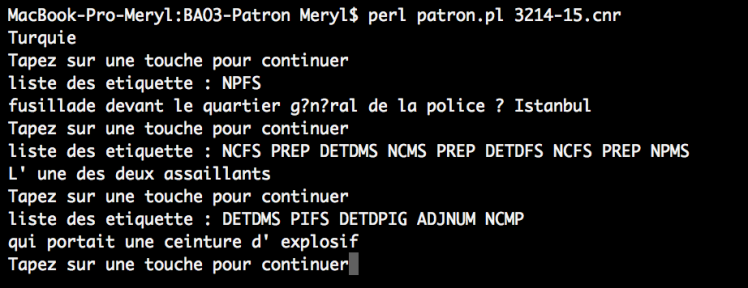
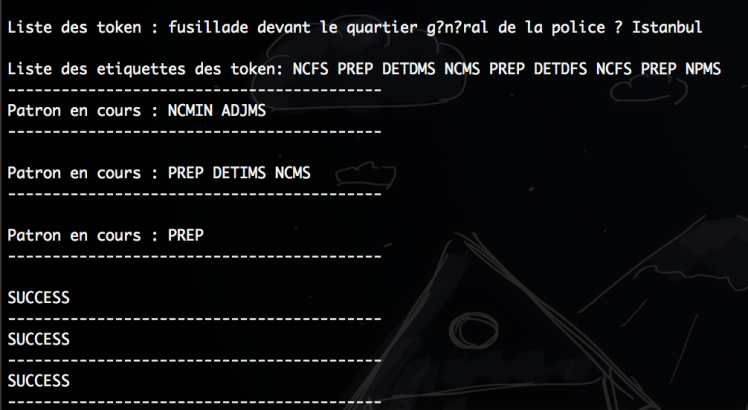
On compare la liste des motifs avec le contenu du fichier Cordial (pour tester le programme on recherche les prépositions qui sont nombreuses…) :
Pas de match :
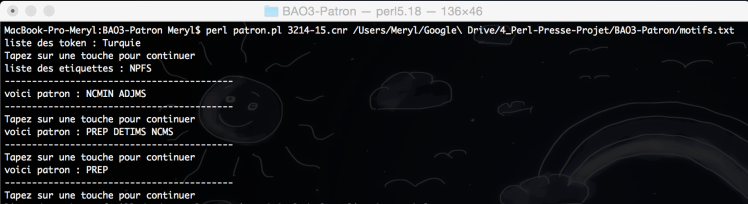
Match :
Séance 6-7 (24/02/16 et 09/03/16)
Objectif du jour : terminer BAO1 et BAO2
Le Monde en Surface :
OK Application n°2 : PROGRAMME PARCOURS n°1 (pur Perl + regexp) – extraire les contenus textuels (des rubriques ici 3208, 3210, 3214) de tous les fichiers RSS de l’arborescence 2015

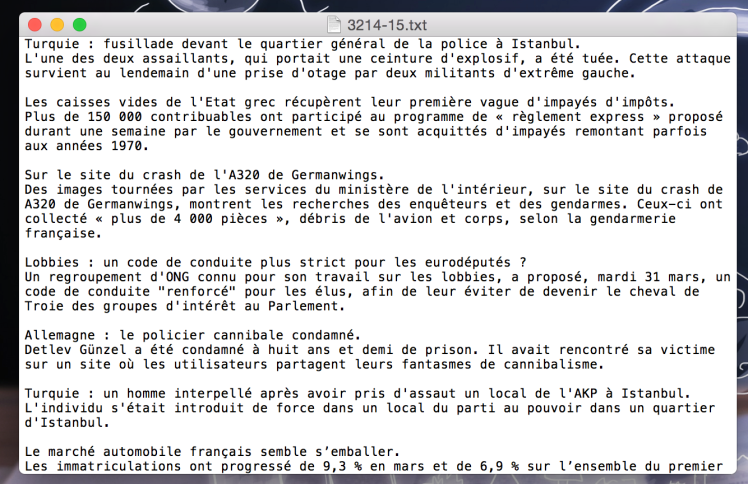
En cours Application n°2bis : PROGRAMME PARCOURS n°2 (via XML::RSS) – extraire les contenus textuels(des rubriques ici 3208, 3210, 3214) de tous les fichiers RSS de l’arborescence 2015
Lancer Active State : sudo /usr/local/ActivePerl-5.16/bin/ppm
Installer la bibliothèque XML::RSS :
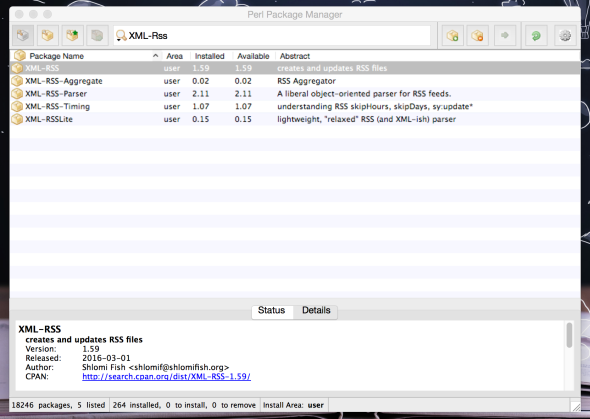
Vérifier son installation : /usr/local/ActivePerl-5.16/bin/perl -e "use XML::RSS" Lancer le programme depuis le terminal : /usr/local/ActivePerl-5.16/bin/perl extract-txt-avec-xml-rss.pl 0,2-3208,1-0,0.xml > resultat.txt
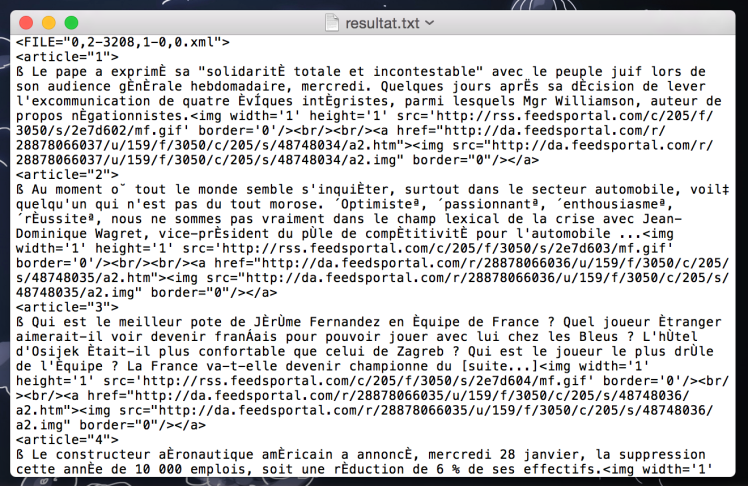
Il y a quelques problèmes d’encodage mais il ne s’agit que d’un fichier test.
Notre corpus 2015 est encodé en UTF-8.
Il faut désormais utiliser notre programme sur toute l’arborescence du corpus 2015 en l’intégrant au programme qui parcours l’arborescence : A FAIRE.
OK Application n°4 : PROGRAMME PARCOURS n°1 (pur perl + regexp) – (1) extraire les contenus textuels(des rubriques ici 3208, 3210, 3214) + (2) étiquetage via treetagger de tous les fichiers RSS de l’arborescence 2015
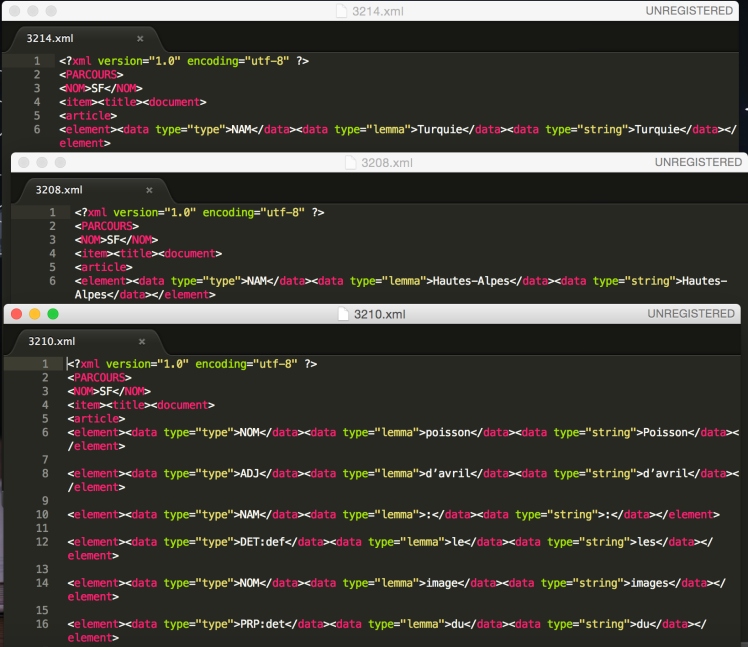
A FAIRE Application n°4bis : PROGRAMME PARCOURS n°2 (via XML::RSS) – (1) extraire les contenus textuels(des rubriques ici 3208, 3210, 3214) + (2) étiquetage via treetagger de tous les fichiers RSS de l’arborescence 2015
OK Les sorties « TXT brut » des programmes de parcours devront être étiquetées avec Cordial
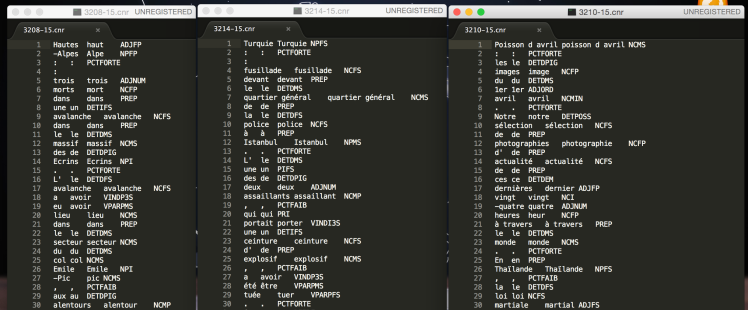
Le Monde Profond :
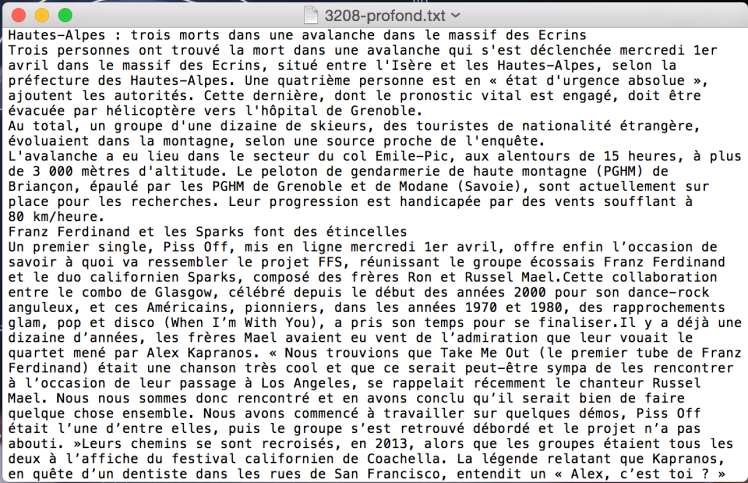
En cours (seulement sur 2016) Application n°3 : PROGRAMME PARCOURS n°3 – extraire le texte complet des articles associés aux fichiers RSS sur l’ensemble de l’arborescence 2015
En cours Application n°4ter : PROGRAMME PARCOURS n°4 (pur perl + regexp) – (1) extraire les contenus textuels (d’une rubrique) + (2) étiquetage via treetagger des articles associés aux fichiers RSS sur l’ensemble de l’arborescence 2015
Etat : il reste encore un peu de nettoyage à faire…
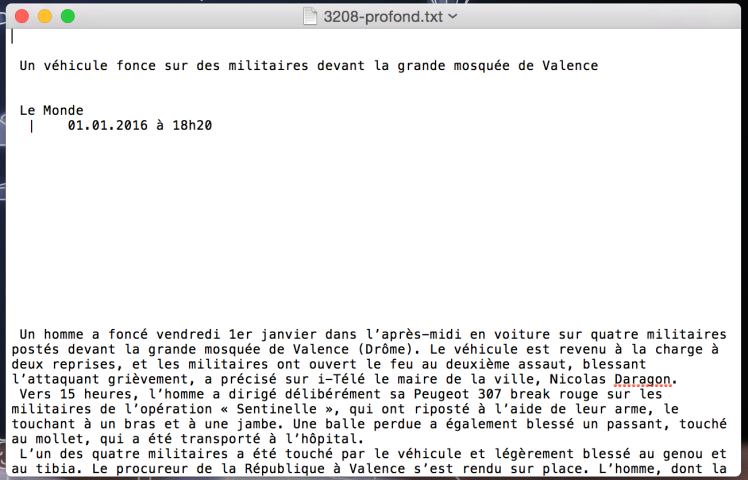
Afin d’écrire la bonne expression régulière pour le nettoyage, rien de mieux que cat -e (permet d’afficher les caractères cachés) pour regarder ce qui nous attend :
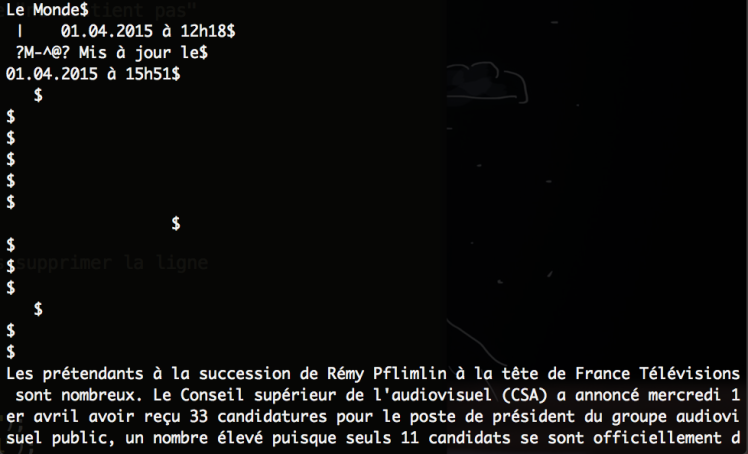
Surprise ! Des $ débutent les lignes vides.
Avancement :
Séance 5 : BAO2 Etiquetage (17/02)
Rappel
La BAO1 a servi à mettre en place une chaîne de traitement.
Nous avons effectué une extraction textuelle des fils RSS de deux manières: 1 programme en Perl et 1 bibliothèque. On ne travaille que sur une rubrique à la fois. C’est la partie extraction en surface. Il faudra ensuite extraire tous les contenus.
A . Le Monde en Surface (les fils RSS)
- Parcours d’arborescence sur le corpus (ici 2016) (Application n°2 : via perl et regexp) et traitement d’une rubrique donnée (ici 3208) :
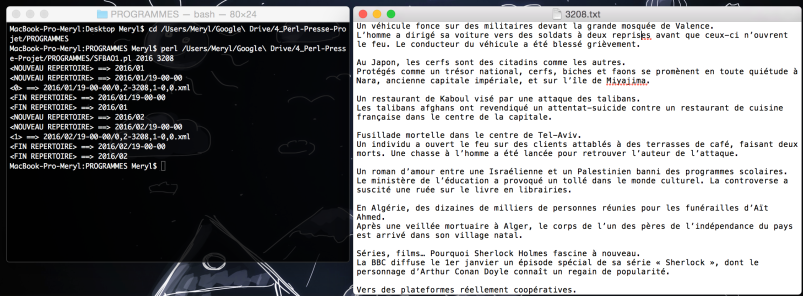
- Parcours d’arborescence sur le corpus complet 2015 (Application n°2bis : via XML::RSS) et traitement d’une rubrique donnée.
Dans les 2 cas, on obtient 2 fichiers en sortie : 1 sortie txt et 1 sortie XML
B. Le Monde profond (les articles complets associés au fils RSS)
- A faire
Ne pas traiter les fichiers cachés (commençant pas .. ou ., ._)
Effectuer un travail de nettoyage sur le fichier de sortie pour la partie profondeur.
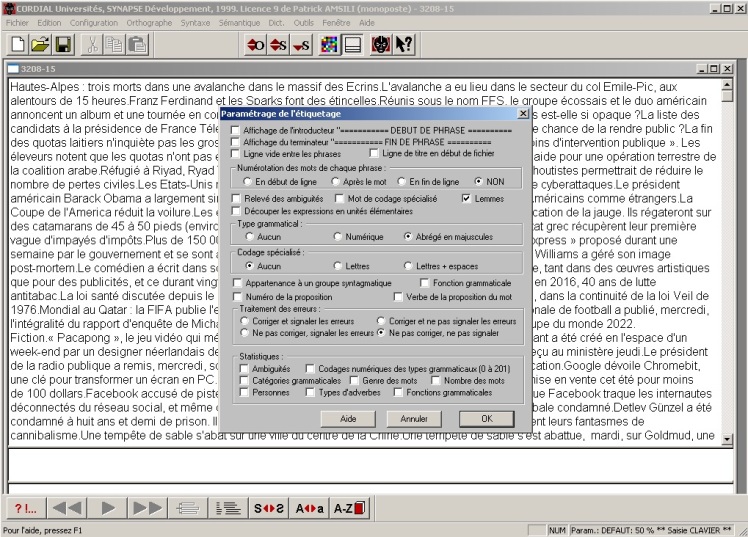
BAO2 : Etiquetage
La sortie .txt sera étiquetée rapidement avec Cordial.
La sortie .xml sera étiquetée au moment du parcours avec TreeTagger (Compter 5h pour 1 rubrique). Nous proposerons les unités sur lesquelles ajouter des étiquettes.
Associer à chaque unité segmentée sa catégorie du discours et son lemme.
Cordial :
En entrée : la sortie textuelle brute (fichier 3208.txt) produite par le programme de la BAO1
Convertir en ISO
Charger dans Cordial
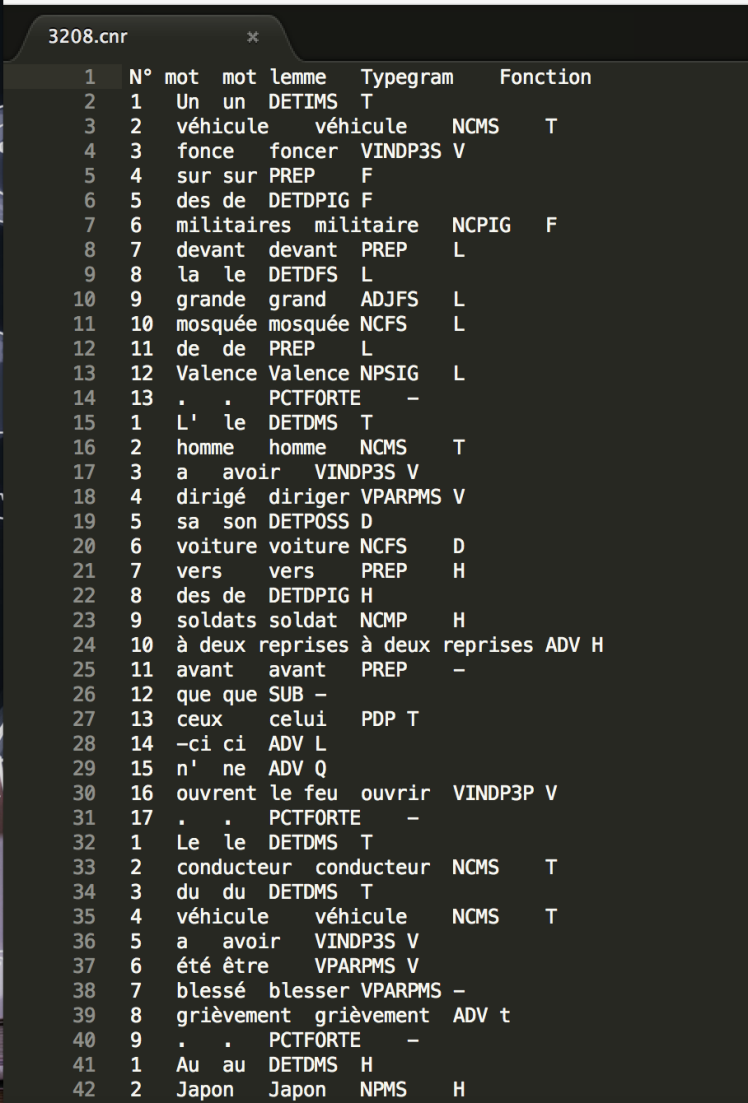
On veut obtenir une liste avec la forme, le lemme et la catégorie.
(Lemmes, Abrégé en majuscules, Codage : Aucun, Ne pas corriger, ne pas signaler)
Treetagger :
Prendre l’exécutable et le mettre dans le répertoire de travail.
Fichier de langue donné par SF.
Le premier paramètre est le fichier de langue, le deuxième est 3208.txt (fichier étiqueté par Cordial). Le fichier à étiqueter devra être segmenté en mot avec un mot par ligne : utilisation du fichier étiqueté de Cordial ou utilisation du programme de segmentation (tokenizer).
Programme Perl qui segmente, un programme qui étiquette, sortie xml
Voir treetagger2xml-utf-8.pl : prend une entrée produite par treetagger et donne une sortie xml.
perl treetagger2xml-utf-8.pl 3208_utf8.treetagger utf8
réécriture du fichier recodé en xml.
Modification du programme d’extraction pour ajouter l’étiquetage (cf. script BAO2)
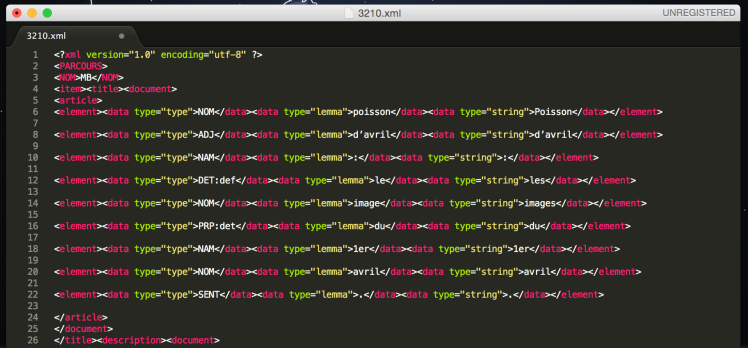
Grâce à ce programme nous obtenons des xml étiquetés avec TreeTagger :
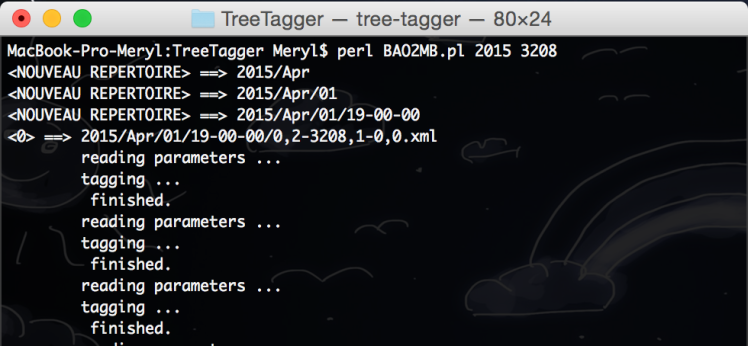

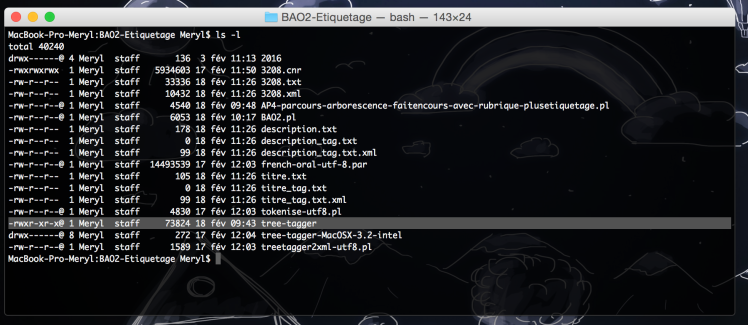
Quelques difficultés ont été rencontrées : il a fallu changer les droits d’exécution sur le fichier tree-tagger :
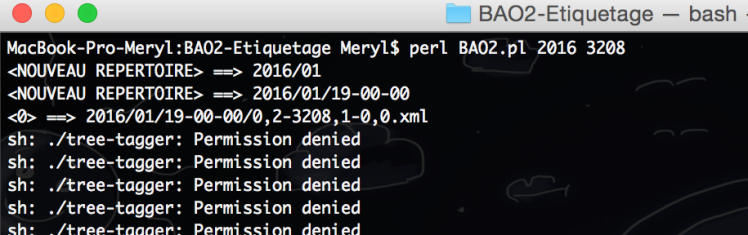
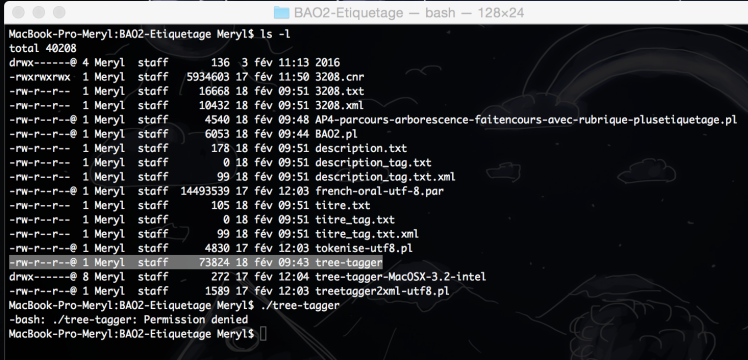
après avoir tapé la commande chmod +x tree-tagger :
Séance 4 (10/02) : fin de la BàO1, POO, Références
Objectif du jour : Utiliser les bibliothèques spécialisées pour parcourir l’arborescence
Bibliothèques spécialisées
Travail sur l’arborescence XML imposée par une grammaire RSS
Réutilisation du code :
CPAN : bibliothèque de modules. Le flux Rss est une structure de données stable : on peut s’appuyer dessus pour traiter des données.
I. POO : programmation orientée objet
Notion d’héritage.
Objet : interface graphique (voiture)
Attribut (dispositif de locomotion) : certains sont cachés, on peut y accéder via des méthodes.
Méthode : permet l’interaction d’un objet avec d’autres objets, mission de message (démarrer, freiner), activer un lien
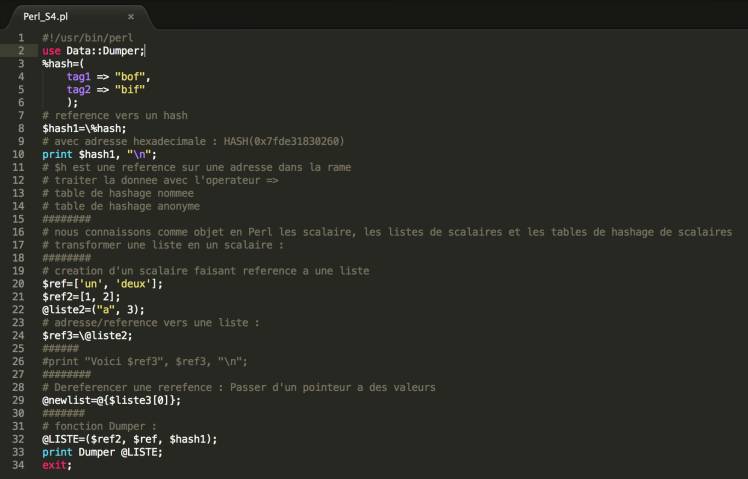
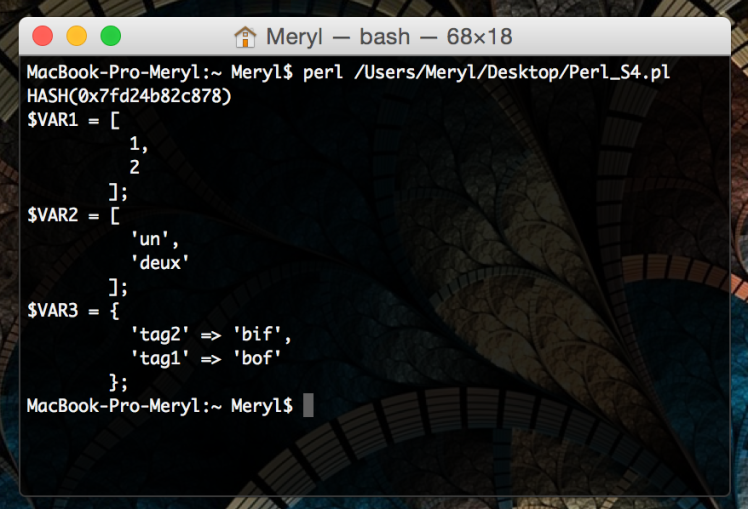
II. Notion de table de hachage : les références
Tout devient scalaire. Très utile pour construire des structures de données. Références anonymes et références nommées.
III. Utilisation de modules dans Perl :
XML::RSS XML::Lib XML
On cherche entre autres à générer des documents ici XML à partir de méthodes dans Perl
Modules Perl
Séance 3 (04/02) : BAO1 (suite)
Objectif du jour : écrire un programme qui va parcourir l’arborescence de fichiers.
Corpus du jour : extrait de 2016, deux journées de RSS pour s’entraîner à traiter l’arborescence. Traiter les articles complets : extraction en texte brut et en xml.

Algorithme :
Dans le répertoire, y a-t-il des fichiers .xml ou .txt ?
Quand on appelle une procédure (avec &), Perl regarde la liste des arguments passés à une procédure : @_ est le nom de cette liste.
La première fois que l’on va l’appeler, on entrera en argument 2016 qui est notre répertoire de travail pour aujourd’hui. Le même code sera lancé mais avec des contenus d’argument par défaut.
La fonction shift enlève le premier élément d’une liste pour le stocker localement.
ls -la : affiche répertoires cachés
. répertoire courant : ne pas y rentrer
.. répertoire parent : ne pas y rentrer
SINON on ne bougera pas. Il ne faut pas les traiter
Structure de contrôle until (jusqu’à ce que la condition soit vraie)
Ce que l’on obtient :
Séance 2 (27/01) : BAO1 – Extraction d’informations
Objectif du jour : rechercher les balises <title> et <descritpion> d’un item.
Difficultés :
– Si le texte visé par le motif est réparti sur plusieurs lignes, le programme risque de se révéler inefficace… Le flux doit être sur une seule ligne.
=> Heureusement Le Monde a évolué : si en 2008 tout ne se trouvait pas sur une seul ligne, en 2015-2016 c’est désormais le cas !
– Le motif de filtrage choisi est-il « le meilleur » ?
=> Maintenant oui !
Faire du rechercher/remplacer:
– Nettoyage du texte (surtout pour le traitement des fils 2015)
=> (cf. « rechercher/remplacer en Perl », notion de procédure en Perl…)
Ce qu’on laisse de côté :
sur l’arborescence 2015 tout est en UTF-8, nous n’avons donc pas besoin de :
– réparer l’encodage (c’était le cas pour les fils de 2008)
– supprimer les éventuels doublons (traitement par des hachages par exemple)
